SAS Made Simple: Using CAS’ Multi-Node Processing to Improve Data Loading
When working with data in SAS Viya you have most likely accessed it via a Caslib. In order to analyse this data, you need to load it into CAS memory. So this is going to be a short guide into how best to achieve this.
There are 2 commonly used methods to do this. You could right click and load the table in the SAS Viya Data Explorer or you could use a code based method with Proc Casutil, for example:
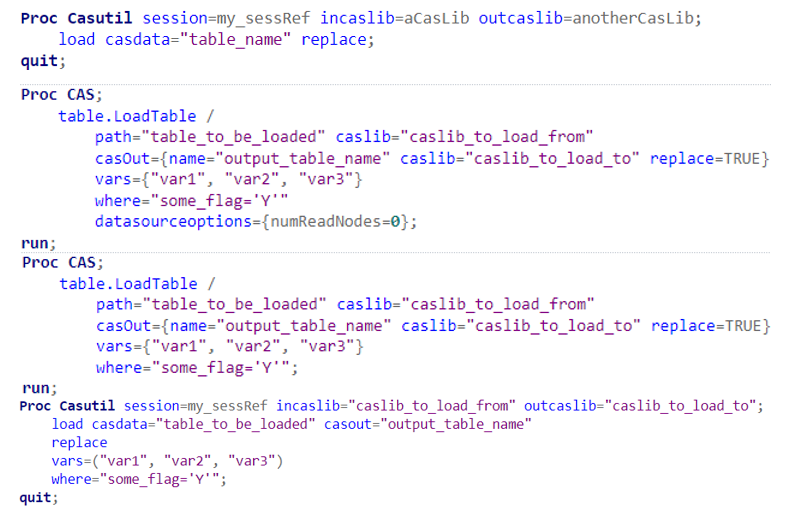
proc casutil session=my_sessRef incaslib=aCasLib outcaslib=anotherCasLib;
load casdata="table_name" replace;
quit;There are two issues with these methods though:
They load the entire table into CAS memory. You can get much better load times by only loading in the data that you need.
They don’t use CAS to its full potential i.e., they don’t use multi-node loading.
We can solve both of these with Proc Cas (CASL), specifically a LoadTable CAS action:
proc cas;
table.LoadTable /
path="table_to_be_loaded" caslib="caslib_to_load_from"
casOut={name="output_table_name" caslib="caslib_to_load_to" replace=TRUE}
var={"var1", "var2", "var3"}
where="some_flag='Y'"
datasourceoptions={numReadNodes=0};
run;This one piece of code will load the fields ‘var1’-‘var3’ of the table denoted by ‘path’ into the caslib listed in the ‘casOut’ statement, and rename the output table if you wish. It is also possible to use a subsetting where statement – note the condition must be enclosed in speech marks.
This is great, we have cut the data down to just the 3 columns we need, while reducing the number of rows to just those where the flag=’Y’, but the really powerful bit of this code is the ‘datasourceoptions’ option.
By default, CAS will load the data using a method called Serial Loading. The data is read in by the Controller Node and then split evenly among the worker nodes.
However, by setting ‘numReadNodes’ to 0 we can tell CAS to directly connect all available worker nodes to the data source and load in parallel. This means the processing can be shared amongst all the workers at once and our data ingestion can be sped up substantially.

Serial Loading

Multi-Node Loading
There are two caveats to consider in regards to multi-node loading though. Firstly, it only works for some database connections.
Databases That Support Multi-Node Loading:
Hadoop
Impala
Oracle
PostgreSQL
Teradata
Amazon Redshift
DB2
MS SQL Server
SAP HANA
The second, is that your data must have a numeric column for the multi-node loading to work. The CAS controller node does some clever maths with a Modulo operation to work out how to split the data, and it uses a numeric column to do this.
If you don’t have a numeric column, or your database hasn’t made the list, then you can still improve your data ingestion by loading in a subset of your data. You can use the Proc CAS example above and drop the ‘datasourceoptions’ line:
proc cas;
table.LoadTable /
path="table_to_be_loaded" caslib="caslib_to_load_from"
casOut={name="output_table_name" caslib="caslib_to_load_to" replace=TRUE}
var={"var1", "var2", "var3"}
where="some_flag='Y'";
run;Or you can add some options to a Proc Casutil. Note the lack of curly brackets and the slightly confusing ‘casout’ statement, which relates to the output table name, not the caslib.
proc casutil session=my_sessRef incaslib="caslib_to_load_from" outcaslib="caslib_to_load_to";
load casdata="table_to_be_loaded" casout="output_table_name"
replace
vars=("var1", "var2", "var3")
where="some_flag='Y'";
quit;
Hopefully this gave you some tips on how to utilise multi-node loading, in order to increase the efficiency of your data ingestion jobs. If you need further help CAS-enabling your code and making the most of parallel processing then please reach out to us at sas@butterflydata.co.uk.